Appendix G: C360
Merge C360 MDM records
One of the biggest issue regarding C360 and its usability and reliability in production environment is due to volume discrepencies. Depending on who the user is and what analysis s/he looks at, it is very likely s/he will be presented with different volumes repernseting the same information.
In order to tackle this issue, the starting point should be hunting, flagging and fixing all duplicates. As stated in the methodology, I used my own records to identify my internal Customer ID; it turns out I have 4 different IDs dating back from 2016, way before C360 went live.
One of the reason for duplicate is due to the first name being abbraviated to the initial; another one is due to the non standard address format: "Lane" instead of "Ln".
I recommend standardizing the matching rules accross various solutions (Melissa, Ataccama, ...), and do a dry run to identify all records that could be merged, flag these records, and either automatically or manually merge them.
In order to track the other duplicates, we could test out several statistical approaches, defining a merge automation above a certain similarity score threshold, and leaving the human in the loop to take care of the records detected but below the threshold.
Standardize customer addresses
This follows the previous paragraph, but focuses on address formats. As of today, several issues have been noted:
- lack of standardization ("Lane" for "Ln")
- inpossible zip codes (out of range or inexistant)
- mismatched zip codes / city
- mismatched city / states
- non standardized state codes
We are able to track some of these issues today, but due to lack of proper access priviledges, we (ADO), cannot fix them.
Simplify Infrastructure
Actual architecure for C360 looks like this:
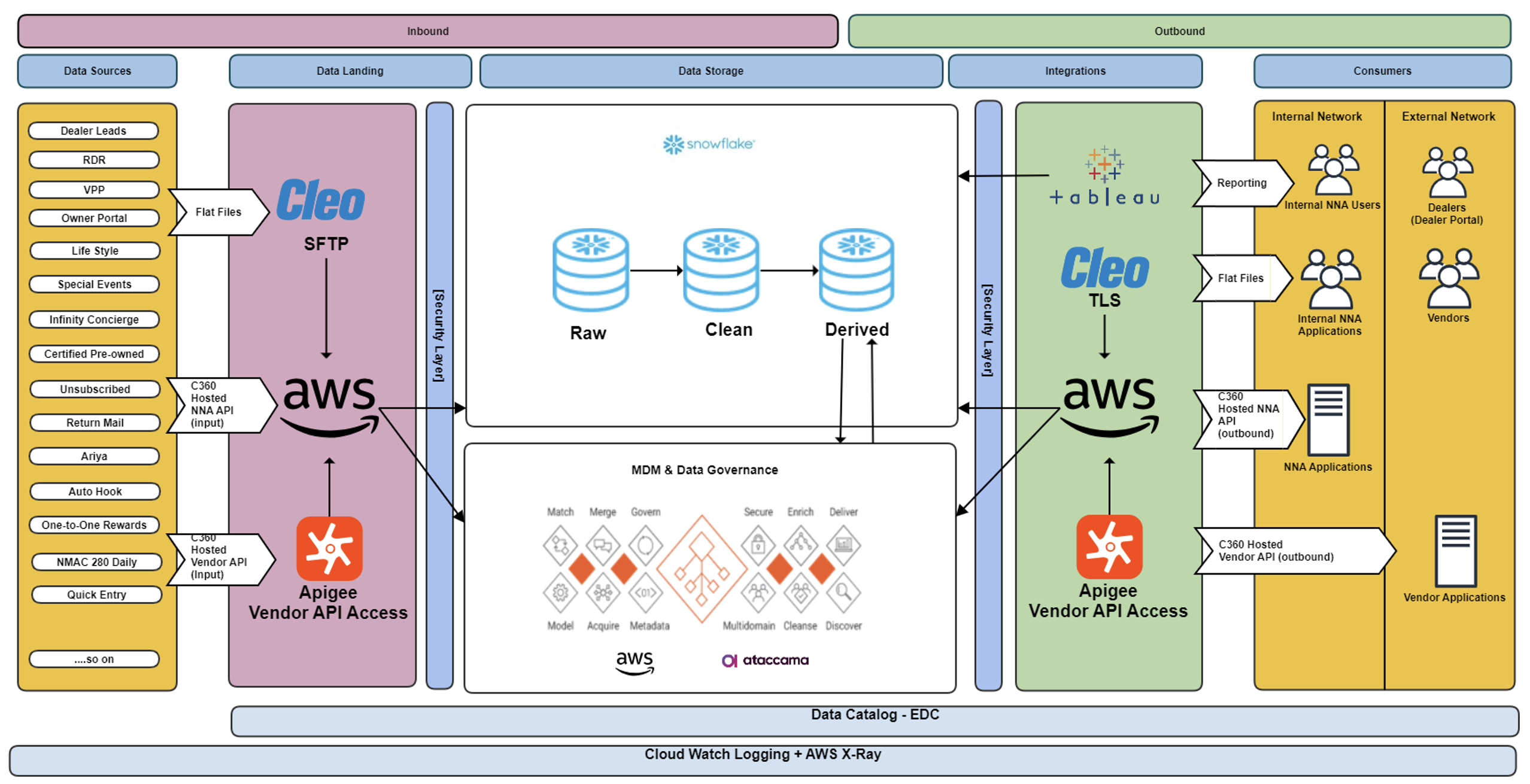
We can identify 6 main processes / steps:
- Input
- Collect
- Ingestion
- MDM
- Publish
- Exploit
The ingestion step contains 4 stages:
- Raw
- Clean
- Derived
- Published
Here is a quick idea of each and their underlying process:
flowchart LR
A[(RAW)] --> B(Validation);
B --> C[(CLEAN)];
C --> D(MDM);
D --> E[(DERIVED)];
E --> F(Preparation);
F --> G[(PUBLISHED)];Nevertheless, there is room for improvement in the collect, ingestion and MDM steps.
The transform stage, step 3, is usually made of a single Lamda function that has several 100s of lines of code. These can be difficult to maintain, that is why breaking them up into smaller, specific steps would be easier. It would also add the benefit or reducing duplicated code.
TODO: check entity tables vs event tables (sale)
Fix data structure and integrity issues
Phone number formats, field length, ... Everyday data gets discarded from importing procedures due to any of these design and minor issues.
This is a 2 day fix, tops!
Create Dev, Pre-Prod and Prod env with regular data drops
Currently, ADO has only a read access to the C360 databases; as such, we can only confirm issues when they are reported by the business. We cannot act one fixes as it would require executing code and possibly write/update/delete data.
Therefore it is crucial for ADO, if it continues to be responsible for C360 and its maintenance, to have sufficent privilegeds to at least evaluate potential fixes.
A lab environment, called "dark prod" is simply a regular copy of the latest state of production environment, with added privileges. The main idea is to be able to thoroughly test fixes which could potentially lead to the complete destruction of the environment in a safe, controlled, and impact-free manner.
This process seems tedious at best, as we get a lot of pushback from ND.
The formal request started on December 2nd.
MISC - To Sort
- CGI and Maritz are being replaced by internal resources, leading to rushed retro engineering
- Over 750 AWS LAMBDA functions
- Over 250 AWS S3 buckets
- Various databases in Snowflake, poorly maintained and not monitored
- Many "shadow" data offices
- C360: (divided into RAW, STAGING, DERIVED and PUBLISHED)
- DERIVED: several deprecated tables (~37 tables out of 173 -> 21%)
- DERIVED: issue on customers linked to severeal cstmr_id
- DERIVED: currently FC_SALE -> cstmr_transctn_mstr_id -> dm_gold_cstmr_lnage
- VINs not found in DBS
- FC_SALE.retail_dt = DBS_SYS.RDR.sl_dt