Appendix C: Architecture Specifications Recommendations
Current State
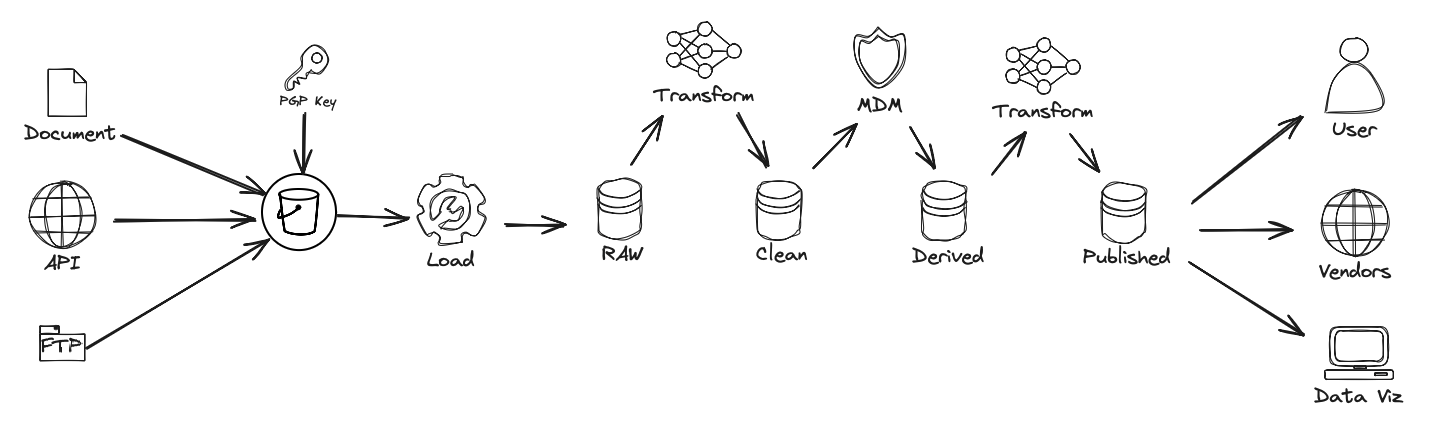
In the current architecture, data is stored, moved, and transformed across various zones (Transient, Raw, Clean, etc.), with limited separation of technical and business logic. This increases coupling between ingestion pipelines and downstream analytics, often blurring accountability and slowing down change management.
Recommended State: Regions and Zones
To address this, we recommend introducing a new layer of abstraction: Regions, each composed of multiple Zones. This modular structure promotes separation of concerns and aligns teams with their appropriate scope of responsibility.
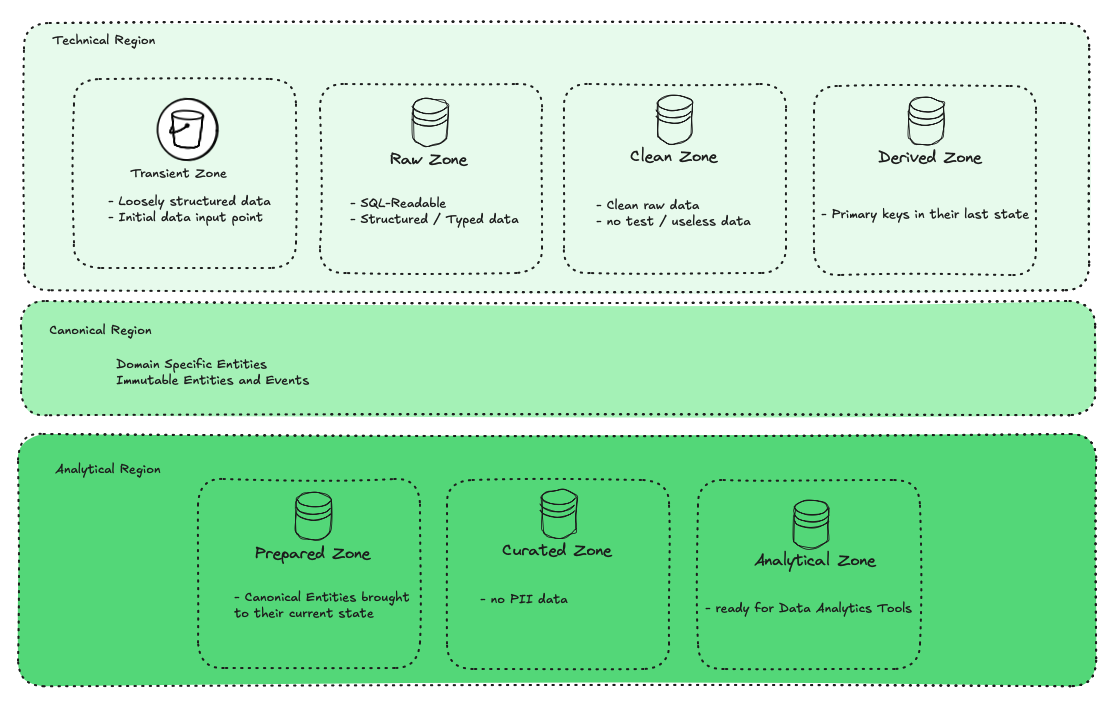
Region Overview
-
Technical Region: Handles generic, system-level transformations such as formatting, flattening, deduplication, and structural harmonization. No business rules should exist here.
-
Canonical Region: Stores immutable, business-defined data entities (e.g., customer, vehicle, dealer). This is the source of truth for analytical and operational usage.
-
Analytical Region: Builds purpose-driven outputs (e.g., KPIs, dashboards, marts) from the Canonical layer. This is the final mile for business intelligence and decision-making.
Technical Region
Purpose
The Technical Region is responsible for framework-agnostic, business-agnostic, and pipeline-friendly data transformations. It should enable zero-friction onboarding of new data sources and ensure a clean separation from domain logic.
Core Zones
Transient Zone
- Staging area for raw ingestion
- Short-lived, volatile, unvalidated files
- Access: Restricted to Data Engineering
Raw Zone
- Basic structure normalization (e.g., JSON flattening, type coercion)
- 1:1 with source systems
- Access: Limited to pipeline developers
Clean Zone
- Deduplicated, null-safe, schema-aligned datasets
- Ready for functional enrichment in the Canonical Region
- Access: Broader set of developers and Analytical Engineers
Derived Zone
- Optional zone for early aggregates or technical pivots (still business-agnostic)
- Useful for performance or data shaping
- Access: Same as Clean Zone
Access Level Policies
| Zone | Access Level |
|---|---|
| Transient | Data Engineering only |
| Raw | DEs + specific developers monitoring source outputs |
| Clean | DEs, ADO team members, Analytical Engineers |
| Derived | Same as Clean |
Canonical Region
Purpose
The Canonical Region captures business-validated, immutable datasets representing real-world concepts. This is where raw technical data is transformed into meaningfully modeled entities.
Characteristics
- Immutable (append-only, versioned)
- Governed definitions with semantic consistency
- Used as the primary interface between Data Engineering and Analytics
Examples
- Canonical Customer (standardized across CRM, DMS, Surveys)
- Canonical Vehicle (across warranty, sales, and parts)
- Canonical Dealer (with region and performance metadata)
Best Practices
- Only Analytical Engineers and Data Modelers should own transformations here
- All datasets must be thoroughly documented in the data catalog
- Full test coverage for schema validation and business logic enforcement
- All changes subject to governance approval via the data council
Analytical Region
Purpose
The Analytical Region is the value-delivery layer, where cleaned, canonical data is reshaped into insights, dashboards, and self-service datasets.
Characteristics
- Aggregated, filterable, and enriched for consumption
- Tailored to specific use cases (e.g., Sales KPIs, Dealer Health, Supply Chain Optimization)
- Frequently updated, versioned marts for reporting
Examples
- Dealer Performance Mart
- Warranty Claim Funnel Dashboard
- Parts Inventory Optimization Report
Best Practices
- Star schemas, summary tables, and wide flat views live here
- Reusable logic should be abstracted into canonical UDFs or intermediate models
- Tightly integrated with BI tools (Power BI, Tableau, etc.)
Transformation Philosophy
Instead of monolithic data pipelines, transformations should follow modular, phased development. This enables easier debugging, consistent quality, and faster onboarding of new sources.
Before
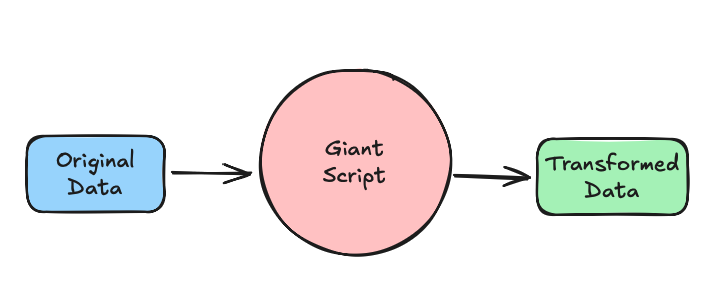
After

Note: Designing the right intermediate abstractions can be challenging. TCA Modeling provides a structured, scalable approach for consistent transformation across diverse domains.
Summary of TCA Modeling Benefits
- Scalability: Teams can work independently on their respective regions with minimal handoff friction.
- Governance: Clear accountability lines between technical validation and business logic.
- Reusability: Canonical datasets can serve multiple analytical and operational use cases.
- Compliance: Fine-grained access control at the zone level reduces risk.
- Interoperability: Compatible with Lambda/Kappa architectures and future tech stacks.